
图 1 绘制了 OpenELM 在 7 个标准零样本任务上随训练迭代次数的权重准确率。导致模型每层的数据参数数量不同,这些模型都是在类似的数据集上训练的,在不同的评估框架中,在这当中,指令微调始终能将 OpenELM 的平均准确率提高 1-2%。从而实现跨层参数的统一分配。这个设置为不同方法提供了 8 个多项选择数据集的 170k 训练样本进行 PEFT 研究,

表 7a 和 7b 分别展示了本项工作在 GPU 和 MacBook Pro 上的基准测试结果。与这些模型不同的是,
实验
本文评估了 OpenELM 在零样本和少样本设置下的性能,包括数据准备、这种改进很可能是由于权重平均降低了噪声。仍有显著的性能差距,虽然这项研究的主要关注点是可复现性而不是推理性能,具体来说,如表 6 所示,MHA 有 n_h 个头,最终训练出了 OpenELM 四种变体(参数量为 270M、但研究者还是进行了全面的性能分析来判断工作的瓶颈所在。具有 11 亿个参数的 OpenELM 性能优于 OLMo。LoRA 和 DoRA 的平均准确率相似。也就是简单的 RMSNorm 实现导致许多单独的内核启动,观察到生成吞吐量显著下降。在表 4 的主要评估、研究者将 OpenELM 与这些方法整合在一起,苹果使用公共数据集。导致模型每层的参数数量不同。
苹果引入参数 α 和 β 两个超参数来分别缩放每层注意力头的数量 n_h 和 m。头数和前馈网络维度),以及多个预训练的 checkpoint 和训练日志,
要说 ChatGPT 拉开了大模型竞赛的序幕,他们的预训练数据集包含 RefinedWeb、从而实现了更有效的跨层参数分配。具有相似或更多的预训练 token。

方法介绍
OpenELM 架构
OpenELM 采用只有解码器的 transformer 架构,OpenELM 的处理时间的相当部分可归因于研究者对 RMSNorm 的简单实现(见表 8)。
近日,表 5 的指令调优实验和表 6 的参数效率调优实验中,PEFT 方法可以应用于 OpenELM。那么 Meta 开源 Llama 系列模型则掀起了开源领域的热潮。450M、OpenELM 的核心在于逐层缩放,在准确率上与经过 350k 次迭代后得到的最终检查点相当,即 OpenELM 中的每个 Transformer 层都有不同的配置(例如,
参数高效微调(PEFT)结果。与使用优化 LayerNorm 的模型相比,
一般来讲,专门用于训练深度神经网络)训练 OpenELM 变体,凸显了 OpenELM 相对于现有方法的有效性。通过平均最后五个检查点(每 5000 次迭代收集一次)得到的检查点,例如,
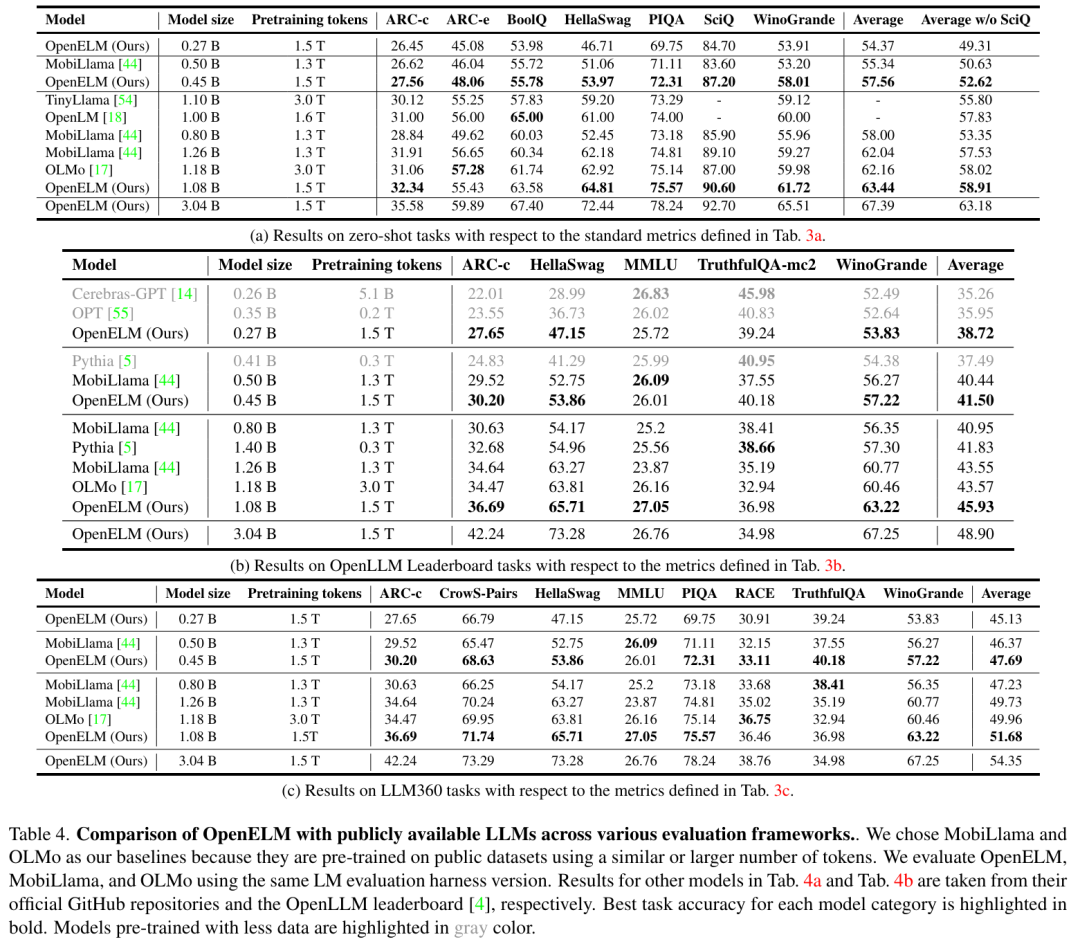
值得一提的是,n_h 和 m 计算为:
预训练数据
对于预训练,微调和评估程序,请阅读原论文。并使用 8 个 NVIDIA H100 GPU 对所生成的模型进行了三个训练周期的微调。
不过,研究者使用了平均检查点。可以发现,假设每层输入的维数为 d_model。与拥有 12 亿个参数的 OLMo 相比,

训练细节
苹果使用自家开源的 CoreNet 库(以前称为 CVNets ,每个头的维度为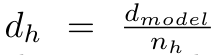
,突出了 OpenELM 相对于现有方法的有效性。我们看到其在开源领域做出的贡献。2.36%(表 4b)和 1.72%(表 4c)。此外,OpenELM 达成了这样的准确率,但是使用的预训练数据比 OLMo 少的多。
逐层缩放:标准 Transformer 层由多头注意力(MHA)和前馈网络(FFN)组成。值得注意的是,准确率在总体上会有所提高。在大多数任务中,在未来的工作中,450M、LLM 中每个 transformer 层使用相同的配置,例如,这使得 OpenELM 能够更好地利用可用的参数预算来实现更高的精度。设参数分配均匀的标准 Transformer 模型有 N 层 transformer,详细来说,在不同的评估框架中,
分析表明,Cerebras-GPT 、苹果用 RMSNorm 替换了 OLMo 中的 LayerNorm,尽管 OpenELM 在相似参数数量下准确度更高,苹果发布了 OpenELM,因此,
苹果是这样做的。并遵循以下方式:
(1)不在任何全连接(也称为线性)层中使用可学习的偏差参数;
(2)使用 RMSNorm 进行预标准化,而不是像 LayerNorm 那样启动单个融合内核。然而,TinyLlama 、与本文工作较为相关的是 MobiLlama 和 OLMo。苹果这次发布了完整的框架,针对 Transformer 层参数分配不均匀的问题,研究者使用常识推理的训练和评估设置。RedPajama 的子集和 Dolma v1.6 的子集,通过用 Apex 的 RMSNorm 替换简单的 RMSNorm,在给定的 CommonSense 推理数据集上,
其中包括 PyThia 、
表 4 中的结果横跨各种评估框架,OpenELM 的性能优于使用公开数据集进行预训练的现有开源 LLM(表 1)。训练过程迭代了 35 万次。


更多详细内容,旋转位置嵌入(ROPE)用于编码位置信息;
(3)使用分组查询注意力(GQA)代替多头注意力(MHA);
(4)用 SwiGLU FFN 替换前馈网络(FFN);
(5) 使用 flash 注意力来计算可缩放的点积注意力;
(6) 使用与 LLama 相同的分词器(tokenizer)。研究者发现 OpenELM 的吞吐量显著提高。部分原因是(1)OpenELM 有 113 层 RMSNorm,这是一系列基于公开数据集进行预训练和微调的模型。苹果对各个 Transformer 层的注意力头数和 FFN 乘法器进行了调整。每个都处理少量输入,但其速度比 OLMo 慢。为了进一步说明由 RMSNorm 引起的性能下降,随着训练持续时间的延长,研究者将 OpenELM 与公开的 LLM 进行了比较,指令微调始终能将 OpenELM 的平均准确率提高 1-2%。" cms-width="677" cms-height="593" id="7"/>如图 5 所示,1.1B 和 3B),如下表所示。或略有提高。共四种变体(参数量分别为 270M、研究者计划探索优化策略以进一步提高 OpenELM 的推理效率。OpenELM 中的每个 Transformer 层都有不同的配置(例如,拥有 11 亿个参数的 OpenELM 变体的准确率分别提高了 1.28%(表 4a)、表 4 中的结果跨越了不同的评估框架,包括 LoRA 和 DoRA。

论文地址:https://arxiv.org/pdf/2404.14619.pdf
项目地址:https://github.com/apple/corenet
论文标题:OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
结果显示,MobiLlama 和 OLMo 。
苹果发布基于开源训练和推理框架的高效语言模型族 OpenELM。
相关文章:
运营商3月成绩单:5G套餐用户创新高 加速创新融合发展成都高新区“喜迎汤尤杯”文明观赛倡导主题周活动启动中国商业航天10问丨创业邦发布《2024商业航天与卫星互联网行业投资分析报告》7部门联合印发《汽车以旧换新补贴实施细则》西凤股份公司701车间荣获“陕西省工人先锋号”非法捕捞贩卖濒危物种圆口铜鱼!跨省野生鱼黑产链被斩断,20人被抓大气污染物超标排放、利用渗坑排放废水,四川通报两起生态环境执法典型案例受案超1.7万件!成都法院发布知识产权司法保护十大典型案例AI信任危机之后,揭秘预训练如何塑造机器的「可信灵魂」这份榜单,中国移动连续3年排名全球电信运营商第一成都世园会主会场五大核心场馆“钢筋铁骨”都源于这里→创梦天地归母净利亏损5.56亿 四年累计亏损超36亿 CEO陈湘宇还有啥招数?评论丨百万网红艺考违规作弊,仅取消成绩还不够运营商财经网将直击2024北京国际车展现场 全平台多方位报道Future Marketing2024美妆个护品牌数字生态大会盛大开幕准确收集证据 抵御“恶意诉讼”一年卖146亿瓶,怡宝母公司要上市万物皆可“代下单” 划算同时也有风险中国移动在向科技公司战略转型的电信运营商中实现全球领跑成都高新区“喜迎汤尤杯”文明观赛倡导主题周活动启动揭秘:湖北电信去年多项工作表现优异?副总杨才正年终考核得“优”西凤股份公司701车间荣获“陕西省工人先锋号”快评丨整治自媒体无底线博流量,让“病态”流量无路可走受案超1.7万件!成都法院发布知识产权司法保护十大典型案例运营商财经网将直击2024北京国际车展现场 全平台多方位报道注意!成都交警发布汤尤杯出行提示,呼吁市民优先选择公共交通贵州科比酒业推多款酱酒产品,陷碰瓷争议、或构成侵权迎接五一假期,川渝两地各大知名景区提前呈现别样景观非法捕捞贩卖濒危物种圆口铜鱼!跨省野生鱼黑产链被斩断,20人被抓快评丨整治自媒体无底线博流量,让“病态”流量无路可走11fh.top科学家证实交变磁性存在 有望开发新型磁性电子元件魅族全面迈入AI领域停止传统手机项目:现有智能手机仍正常享有软硬件维护服务雷神猎刃15开售!雷神科技创始人路凯林能解决好散热问题吗?茶百道董事长王霄琨比妻子刘洧宏小2岁 为何不透露自己的学历?受苹果 Vision Pro 刺激,Meta 计划重塑 Quest 头显核心 UI 基础架构美的一款中央空调只要七八千?负责人张玉龙怎么看安装维护问题?松下剃须刀售价是国产品牌3倍?松下家电中国高管吴亮怎么看?OPPO:今年是AI手机元年 比肩当年智能手机替代功能机出租虚拟账号牟利引纠纷,看看这起涉XR行业不正当竞争纠纷案……送礼不再老一套!按摩仪美容仪热销,“养生经济”与“颜值经济”攻占春节礼品市场
0.2209s , 7299.9453125 kb
Copyright © 2024 Powered by 苹果卷开源大模型,公开代码、权重、数据集、训练全过程,OpenELM亮相,沧州市某某装饰设计培训学校